

硅谷大數據科學家:標準化數據產品有哪些典型架構?|微課干貨
修平平
2015-10-13
如果想要了解數據產品的典型架構,首先要還原什么是傳統產品的典型架構。搞互聯網的可能都應知道Restful,即表征狀態傳輸的概念。基本的機身是http的請求是沒有內部狀態的。那么我在http請求里面,通過一些參數指定提交請求之后,返回的內容是確定性的。優勢在于可以把產品做的規模化、適應流量增加達到互聯網的規模的時候,仍然能夠適應。

這里給大家一個案例。
這是一個非常知名的互聯網的企業。它以提供某個行業非常正統的信息服務給消費者。主要流量是以瀏覽的形式。用戶在它的網頁上去欣賞它的內容。它的背后就是表征狀態傳輸的架構。我們今天通過該課程來對其傳輸的過程進行描述。
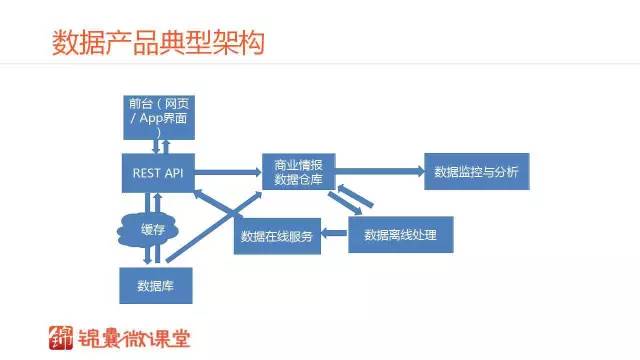
這是我理解中數據產品的典型的組件。相對傳統的表征狀態傳輸的架構,它幾乎具有所有的表征狀態傳輸的架構。包括前端、后端、API層、緩存層以及數據庫層。還有數據相關的四個組件是數據倉庫、商業情報、數據監控與分析、數據離線處理和數據在線服務。

這幾個層有不同的作用。商業情報層主要是管信息整合,數據監控與分析層管運營,數據離線處理是信息的二次加工,數據在線服務是數據驅動產品體驗。這幾個層是數據產品能夠轉起來的最基本的組件。稍后我會結合案例進行深入分析,現在我們先來看一看每個層的作用。

商業情報層是數據倉庫,是一種特殊的數據庫。是專門用于做數據分析和決策的數據庫。它和傳統的數據庫有本質的區別。傳統的數據庫,它的ER設計是一個現實過程的還原。所以你看到ER圖之后,你就能夠知道它的過程、流程到底是什么。最主要特點是高度正則化。
商業情報系統是大數據技術的典型應用場景。之后的一些大數據的技術都是受商業情報系統設計的一些啟發。最知名的參考書就是《數據倉庫工具箱》。它的核心概念是數據倉庫或者商城系統是提高商業決策的基礎。他的數據表在設計的時候是動態變化、可拓展性的。就是為了做數據分析。這個和ER的設計概念完全不一樣。它的數據表結構的設計原則是為了查詢簡化和數據的復用。能夠支持敏捷的做各種各樣的數據之間關聯性的調查。

在商業情報的基礎上,我們還有數據監控與分析層。在大數據時代之前,數據監控與分析的主要工具就是Excel。具體的說就是透視表和回歸分析工具。那么R就是統計分析標準語言,適合做模型的評估比較。對相關人員的技能要求高是因為需要做一些建模。
一些基于Web的服務能夠使大家實現對數據可視化、實時化與共享性。我列出來的一些都是在大數據時代做數據監控與分析的典型的第三方Web Service。比如,有一些是適合做商業高層數據的分析的。Google Analytics是做廣告的。Splunk是做點擊優化與網站內容優化的。還有AppDynamics是負責網站運營、運行監控的。它的特點的更多的人員能夠參與到數據分析之中。不管是公司的高級管理人員還是運營、網站監控、數據分析師都能使用一套工具來進行數據分析和共享。

數據離線處理一定要提到Google的三駕馬車。Google在十年之前陸續發表了三大經典論文。這是進入大數據的時代的標志。GFS就是使用非高端硬件實現大數據存儲。MapReduce (大排序)歸并排序MergeSort應用在小內存。BigTable準關系數據庫,支持寬表(Wide Table), 列簇(Column Families);適合數據倉庫。
當時最主要的時代背景是大量的非高端硬件普及。非高端的硬件實現了非常可靠的數據存儲。排序技術是最主要的數據分析引擎。MapReduce 是最本質的一種排序,歸并排序。
那么哪一點是新的呢?本質上說都是原來的技術,只不過是在硬件上實現了突破。其實排序技術是最古老的算法。它能夠使大量硬件在小內存實現規模化。這一點就奠定了大數據時代。其實在上層,所有的數據分析都可以歸結為排序算法。
所有的數據分析,如果在排序上面能夠做得非常規模化,能夠處理非常大的數據量,那么所有的上層應用,數據分析都能夠做得非常棒。從這一點上說,大數據技術并非非常神秘。本質上都是歷史上已經有的技術,因為現在硬件的突破使得我們現在能夠處理非常大的數據集。

Google的這些技術已經有十多年的歷史了。隨著技術的進步,產業出現了一些新的環境。比如內存的發展,我們現在有了更多的內存,可以有更多的優化空間。另外從商業來說,實時性的要求提高了。最典型的就是社交網絡,尤其是微信和Twitter這些都要求實時性的提高。所以近年來流計算技術(Streaming)的發展就是最近新出現的技術。它其實就是對數據排序的優化。
因為我們現在有了更多的內存了,所以MapReduce的一個操作運行完都寫在磁盤上,對于數據的重復使用上是不優化的。實際上,很多MapReduce是在一起運行的,所以就存在很多的優化空間。就是我現在內存中的數據可以不寫回硬盤,但是可以執行下一個操作。
同時MapReduce并沒有考慮到實時性的需求。由此產生了Storm。Storm和Spark不一樣,數據是在內存中以實時流的形式,在預先設定的拓撲中流動。其實MapReduc很大的瓶頸是在對數據發生扭曲的時候,一些實時性的問題。Storm對實時性的優化實現了對MapReduce在實時性上的優化。
一、機器學習

剛才說的是大數據,還有一種離線處理是機器學習。機器學習在數據產品中的作用就是從歷史海量數據中學習規律。這種規律的是以模型的形式存在。它能夠推送在線上,在線上環境中快速生成決策。
機器學習這一門學問是博大精深。有半個世紀的發展和很多算法。在商業應用中主要是做決策樹和邏輯回歸。決策樹適合在樣本少量的情況下,便于調試。我們最先開始引入機器學習技術,那么建議先用決策樹。Vappal Wabbit是一種邏輯回歸工具,偏重于自然語言理解,需要大量樣本。最主要的優勢在于用單機就可以運行,能處理非常大的數據集。
二、在線服務

傳統的在線服務就是RESTful API,主要就是數據庫+緩存。因為數據是需要更新的,需要適應動態變化。更新機制傳統的最簡單的就是清除緩存,重新查詢數據庫,還有基于批處理和消息隊列。那么在大數據時代,最主要的在線服務就是通過Key-Value Store。這也是最古老的一種數據結構。
現在一些非常知名的開源的軟件,比如 S3,DynamoDB,Cassanda。本質上其實都是在online的時候能夠實現非常可靠的、規模性的一些Key-Value Store的查找。
回到我們最開始的案例。這個傳統企業有一些內容是通過數據庫的形式存在。需要通過規模化提供Web的服務。它采用了Restful這種典型的架構。這是有痛點的。比如,我在前臺的時候,需要有許多的用戶需求。其實后臺是需要服務于前臺的。前臺需要用戶不斷的提出新的頁面需求。意味著數據通過新的呈現方式展現。這個對后臺的壓力非常大,因為后臺不能直接通過正則化的數據庫服務出去。你需要通過一些中間的數據表,是去正則化的。是為了前臺去定制的,說這就帶來了很復雜的后臺。還要保證正則化的表和非正則化的表之間的怎么去數據,才能夠達到一致性的問題。這就使得他們越來越慢,越來越多的開發都在后臺上。
現在大數據時代到來了。我們提到了這么多組件。這個企業是怎么轉型的呢?首先是在離線處理的這個模塊,把數據庫從正則化的數據庫直接用離線處理大數據的平臺去做好前臺的網頁。從中間的數據庫去正則化的表都用大數據生成了。所以第一個階段取得的成果在于極大的簡化了后臺。是大數據的離線處理使得我不需要維護非常復雜的后臺就能夠支持前臺。因為我的后臺處理就是MapReduce的技術來實現的。
有一個很壞的事,他又進入了下一個痛點。每一次改了正則化的數據庫都需要等一天的時間。因為離線處理是每天執行一次的。每天最新的更新需要積攢起來等下一班的數據離線處理,才能夠推送給服務端。不能很快的去響應用戶的需求。
所以為了讓實時性的要求提高。它又采用了數據在線服務方面的Key-Value Store。那么它通過消息隊列把后排當中數據庫的變化消息能夠在查找表中得到更新。在API層,會現在查找表中去檢查是不是最新的更新。如果是最新更新就直接從在內存中的查找表返回數據。否則,就會在到批處理的數據中找到返回數據。所以還是需要離線處理,但是應用了在線的查找表,把時間縮短到了幾分鐘之內。
這是一個比較好的轉型。在線額離線處理結合。首先通過離線處理使后臺得到了極大的簡化。同時又使用在線服務,實現了快速在服務端顯示后臺更新。結合之下,達到了真正的數據產品。這是一個典型的案例,最核心的就是從離線處理出發。但是離線處理需要一個非常好的數據源。所以一定要把你的商業情報和數據倉庫這一層設計好。然后使用一些第三方應用去實現數據的實時監控。
同時最挑戰的是怎么把離線處理的結果推送到在線?實現的是數據的在線服務。這里面有一些機器學習的成分。一般的策略就是從簡單的、經典的學習算法入手了,逐漸根據需求上更加復雜和更大的數據輸入才能轉起來的算法,比如深度學習。
文章為「錦囊專家」原創作品,歡迎轉載。作者: 修平平。
- 案例
- IT/互聯網
- 軟件信息
- CEO
- CTO
- CDO
- IT
- 大數據
- 協同辦公




推薦

11月28日-30日,中國數字化年會將于成都正式開幕,本屆年會以數智萬象 無界新生”為主題,設置2場主論壇、1場高峰論壇、5場專題論壇、4項特色活動、2場頒獎典禮等14項活動,以及2天數字化轉型供需對接展。

零次方科技發布了其首款人形機器人,可以在多種不規則路面、復雜地形中長時間穩定行走,且具備優秀的抗干擾性能,即使受到各方向的強沖擊也能保持穩定站立。

近日,第四屆“青年科學家502論壇”在南方科技大學舉行,美國國家工程院外籍院士沈向洋做了《通用人工智能時代,我們應該怎樣思考大模型》的主題演講,并給出了他對大模型的10個思考。
深度解析Meta Reality Labs的生態布局
TeleAI 李學龍團隊提出具身世界模型

2024 年 10 月 14 日,第 44 屆中東海灣信息技術展(GITEX Global)在阿聯酋迪拜開幕。紫光股份旗下新華三集團重磅亮相展會,以"精耕務實,為時代賦智慧"為主題,全面展示了公司"云-網-安-算-存-端"的全棧技術能力與國際生態合作成果。



 15355
15355 15283
15283 17671
17671 16758
16758 15110
15110 13853
13853
修平平
Salesforce
首席數據科學家
Salesforce 首席數據科學家
現任職 Salesforce 首席數據科學家。在Amazon、Microsoft 有多年工作經驗,擔任商業搜索部門的數據科學部門(Revenue and Relevance)的項目帶頭人。
TA的主頁




我要評論