

人類數據,要被 OpenAI 用完了,然后呢?
2023-07-17
來源:極客公園
作者 | 湯一濤
編輯 | 靖宇
「比大更大」(Bigger than bigger)當年蘋果的一句廣告詞,用來形容現在 AI 領域最熱的大語言模型,看起來也沒什么不對。
從十億、百億再到千億,大模型的參數走向逐漸狂野,相應的,用來訓練 AI 的數據量,也以指數級暴增。
以 OpenAI 的 GPT 為例,從 GPT-1 到 GPT-3,其訓練數據集就從 4.5GB 指數級增長到了 570GB。
不久前的 Databricks 舉辦的 Data+AI 大會上,a16z 創始人 Marc Andreessen 認為,二十幾年來互聯網積累的海量數據,是這一次新的 AI 浪潮興起的重要原因,因為前者為后者提供了可用來訓練的數據。
但是,即便網民們在網上留下了大量有用或者沒用的數據,對于 AI 訓練來說,這些數據,可能要見底了。
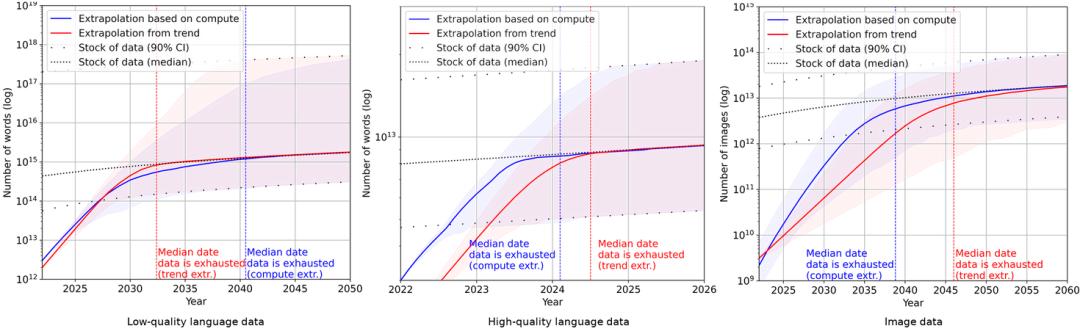
人工智能研究和預測組織 Epoch 發表的一篇論文里預測,高質量的文本數據會在 2023-2027 年之間消耗殆盡。
盡管研究團隊也承認,分析方法存在嚴重的局限,模型的不準確性很高,但是很難否認,AI 消耗數據集的速度是恐怖的。
當「人類」數據用完,AI 訓練不可避免地,將會使用 AI 自己生產的內容。不過,這樣的「內循環」,卻會產生很大挑戰。
不久前,來自劍橋大學、牛津大學、多倫多大學等高校的研究人員發表論文指出,用 AI 生成的內容作為訓練 AI,會導致新模型的崩潰。
所以,AI 訓練用「生成數據」會帶來崩潰的原因是什么?還有救嗎?
AI「近親繁殖」的后果
在這篇名為《遞歸的詛咒:用生成數據訓練會使模型遺忘》的論文中,研究人員指出,「模型崩潰」是一個幾代模型的退化過程。
前一代模型生成的數據,會污染下一代模型,經歷幾代模型的「傳承」,它們就會錯誤地感知世界。
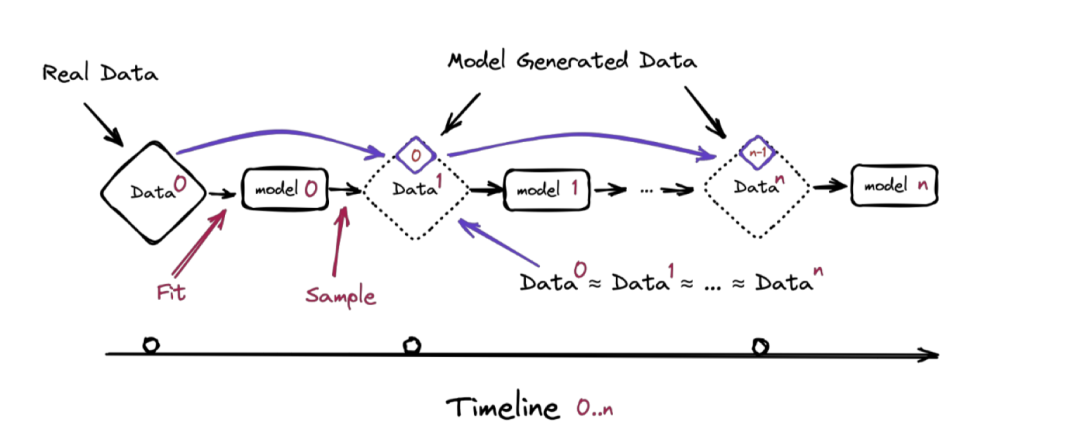
模型迭代示意圖|arxiv
模型崩潰分為兩步:
在早期模型崩潰中,模型會開始失去原始數據的分布信息,也就是「干凈的人類數據」;
在晚期,模型會把上幾代模型對原始分布信息的「錯誤認知」糾纏到一起,從而曲解現實。
研究人員首先從頭訓練了小樣本模型 GMM(高斯混合模型)和 VAE(變量自動編碼器)。以 GMM 為例,下圖最左是原始數據的正態分布。
可以看到,模型一開始對數據的擬合非常好。到第 50 次迭代時,基礎數據分布開始被錯誤感知。當迭代來到 2000 次時,模型已經收斂到一個很小的點,這意味著模型開始穩定輸出錯誤答案
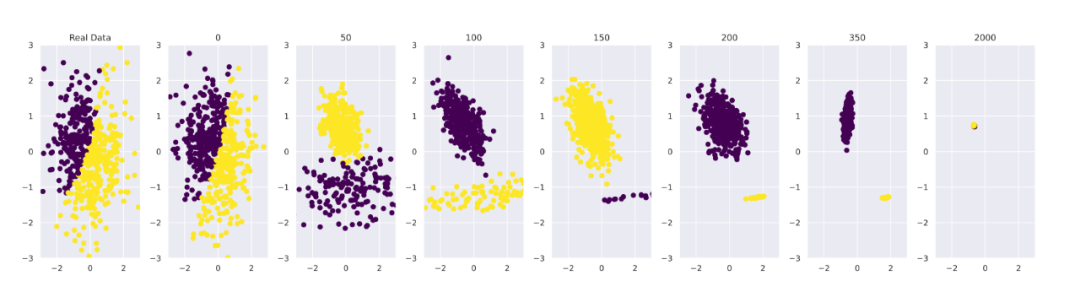
GMM 在迭代 0、50、100、150、200、350、2000 時擬合數據的例子|arxiv
為了驗證預訓練對實驗結果的影響,研究人員又在 Meta 開發的 1.25 億參數的 LLM(大語言模型)OPT-125m 上進行了實驗,數據集來自維基百科的 wikitext2。
和 GMM、VAE 這類小模型不同,LLM 從頭訓練的成本非常高,所以它們都是經過預訓練的。實驗結果如下:

輸入:根據 Poyntz Wright 的說法,在 1360 年之前有些活動通常由一位主要石匠和一小隊流動的石匠完成,輔以當地教區勞工。但其他作者則否認了這種模式,相反提出主建筑師借鑒英國垂直式風格設計了教區教堂的尖塔。
輸出:
第 0 代:復興建筑,例如倫敦的圣約翰大教堂。現存最早的垂直復興建筑可以追溯到 18@-@ 世紀的根西島圣母教堂,該教堂建于 19 世紀末。有兩種類型的垂直式教堂:那些
第 1 代:建筑,如羅馬的圣彼得大教堂或布宜諾斯艾利斯的圣彼得大教堂。沒有證據表明這些建筑 是在教皇英諾森三世統治時期建造的,但有可能是在他的繼任者英諾森教皇統治時期建造的。
第 7 代:英國的建筑。在接受《紐約時報》采訪時,賴特說:"我不認為我能夠做我想做的事情有什么問題。它只是對我不起作用。"他補充說:"我不知道你是否可以稱之為有趣、
第 9 代:建筑。除了成為全球黑 @-@ 尾巴大野兔、白 @-@ 尾巴大野兔、藍 @-@ 尾巴大野 兔、紅 @-@ 尾巴大野兔、黃 @-的最大棲息地之一
可以看到,到第 9 代模型時,輸出的內容已經完全不知所云。
論文的作者之一 Ilia Shumailov 說,隨著時間的推移,人工智能生成的數據中的錯誤不斷累積,主要的模型在接受這些數據的訓練后,會對現實產生更加扭曲的看法。
為什么會模型崩潰?
「模型崩潰」產生的最主要原因,還是因為 AI 并非真正的智能,它展現出的近似「智能」的能力背后,其實是基于大量數據的統計學方法。
基本上,所有無監督機器學習算法都遵循一條簡單的模式:給定一系列數據,訓練出一個能描述這些數據規律的模型。
這個過程中,訓練集里更大概率出現的數據就更容易被模型重視,小概率出現的數據就會被模型低估。
舉個例子,假設我們需要記錄 100 次骰子的投擲結果,來計算每個面出現的概率。理論上,每個面出現的概率是一樣的。在現實生活中,由于樣本量較小,可能 3、4 出現的情況比較多。但對于模型而言,它學習到的數據就是 3、4 出現的概率更高,因而會傾向于生成更多的 3 和 4 的結果。
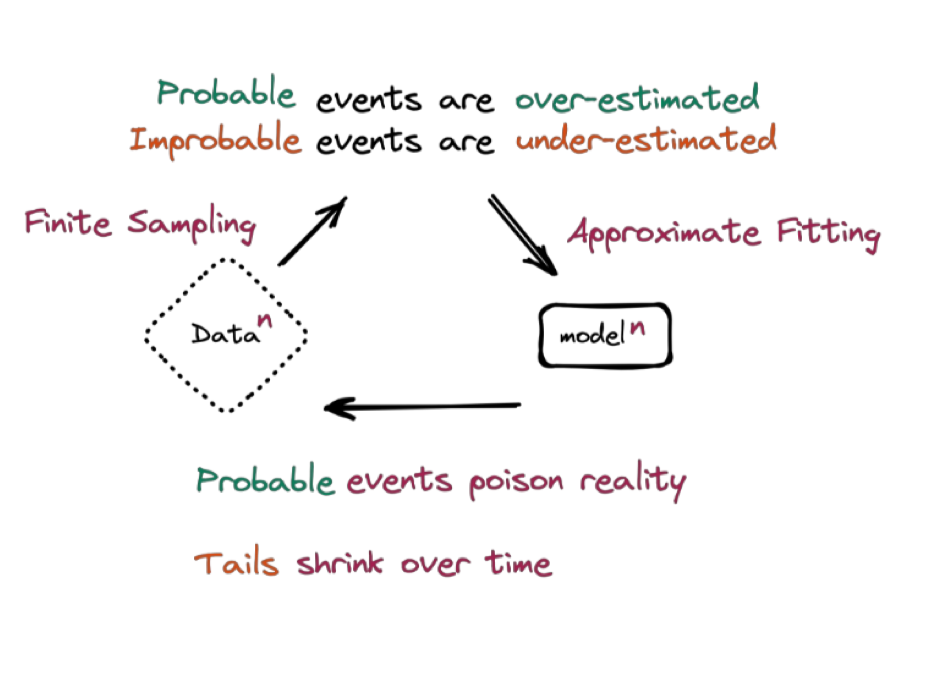
「模型崩潰」示意圖|arxiv
另一個次要原因是函數近似誤差。也很好理解,因為真實函數往往很復雜,實際運用中,經常使用簡化的函數來近似真實函數,這就導致了誤差。
真沒招了嗎?
杞人憂天!
所以,在人類數據越來越少的情況下,AI 訓練真的沒機會了嗎?
并不是,用于訓練 AI 數據枯竭的問題,還有方法能解決:
數據「隔離」
隨著 AI 越來越強大,已經有越來越多的人開始使用 AI 輔助自己工作,互聯網上的 AIGC 爆炸式增長,「干凈的人類數據集」可能會越來越難以找到。
谷歌深度學習研究部門谷歌大腦 Google Brain 的高級研究科學家 Daphne Ippolito 就表示,在未來,要找到高質量、有保證的無人工智能訓練數據將變得越來越棘手。
這就好比是一個患有高危遺傳病的人類始祖,但是又擁有極其強大的繁殖能力。在短時間內他就把子孫繁衍到了地球每一個角落。然后在某一時刻,遺傳病爆發,人類全體滅絕。
為了解決「模型崩潰」,研究團隊提出的一種方法是「先行者優勢」,也就是保留對干凈的人工生成數據源的訪問,將 AIGC 與之分隔開來。
同時,這需要很多社區和公司聯合起來,共同保持人類數據不受 AIGC 污染。
不過,人類數據的稀缺意味著這其中有利可圖,已經有一些公司行動起來了。Reddit 就表示將大幅提高訪問其 API 的費用。該公司的管理人員表示,這些變化 (在一定程度上) 是對人工智能公司竊取其數據的回應。Reddit 創始人兼首席執行官 Steve Huffman 告訴《紐約時報》:「Reddit 的數據庫真的很有價值。」「但我們不需要把所有這些價值都免費提供給一些全球最大的公司。」
合成數據
同時,專業基于 AI 生成的數據,早已有效用于 AI 的訓練。在一些從業者看來,現在擔心 AI 生成的數據會導致模型崩潰,多少有點「標題黨」。
光輪智能創始人謝晨告訴極客公園,國外論文提到的,用 AI 生成數據訓練 AI 模型導致崩潰,實驗方法比較偏頗。即便是人類數據,也有能用和不能用之分,而論文提到的實驗,則是不加分辨地直接用來訓練,而并非有針對性的經過質檢、效用性判定后作為訓練數據,顯然有可能會造成模型崩潰。
謝晨透露,其實 OpenAI 的 GPT-4,就采用了大量前一代模型 GPT-3.5 生產的數據來進行訓練。Sam Altman 也在近期的采訪中表達,合成數據是解決大模型數據短缺的有效方法。而其中的關鍵在于,有一整套體系來區分 AI 生成的數據中,哪些可用,哪些不可用,并不斷根據訓練后模型的效果進行反饋——這是 OpenAI 能笑傲 AI 江湖的絕招之一,這家公司并不只是融的錢多,買的算力多這么簡單而已。
在 AI 行業內,使用合成數據來進行模型訓練,早已經成為一個尚未為外人所知的共識。
曾經在英偉達、Cruise、和蔚來等公司負責自動駕駛仿真的謝晨認為,以目前各種大模型訓練的數據量來看,未來 2-3 年,人類數據確實有可能「枯竭」,但是基于專業化體系和方法,AI 生成的合成數據,會成為用之不竭的有效數據來源。并且使用場景并不局限于文字和圖片,像自動駕駛、機器人等行業需要的合成數據量,將遠遠大于文本的數據量。
AI 三要素,數據、算力、算法,數據來源有著落了,算法大模型在不斷進化,唯一剩下的算力壓力,相信英偉達創始人黃仁勛是可以順利解決的。
- 推薦
- 案例
- IT/互聯網
- CIO
- CDO
- 戰略
- IT
- 人工智能
- 大數據




推薦

11月28日-30日,中國數字化年會將于成都正式開幕,本屆年會以數智萬象 無界新生”為主題,設置2場主論壇、1場高峰論壇、5場專題論壇、4項特色活動、2場頒獎典禮等14項活動,以及2天數字化轉型供需對接展。

零次方科技發布了其首款人形機器人,可以在多種不規則路面、復雜地形中長時間穩定行走,且具備優秀的抗干擾性能,即使受到各方向的強沖擊也能保持穩定站立。

近日,第四屆“青年科學家502論壇”在南方科技大學舉行,美國國家工程院外籍院士沈向洋做了《通用人工智能時代,我們應該怎樣思考大模型》的主題演講,并給出了他對大模型的10個思考。
深度解析Meta Reality Labs的生態布局
TeleAI 李學龍團隊提出具身世界模型

2024 年 10 月 14 日,第 44 屆中東海灣信息技術展(GITEX Global)在阿聯酋迪拜開幕。紫光股份旗下新華三集團重磅亮相展會,以"精耕務實,為時代賦智慧"為主題,全面展示了公司"云-網-安-算-存-端"的全棧技術能力與國際生態合作成果。



 15355
15355 15283
15283 17671
17671 16758
16758 15110
15110 13853
13853




我要評論