

微軟中國CTO韋青:親身經(jīng)歷大模型落地的體會與思考
2024-07-15
來源: AI前線
演講嘉賓 | 韋青 微軟(中國)公司 / 首席技術官編輯 | 蔡芳芳 傅宇琪
在大模型、AIGC 的沖擊下,大多數(shù)人把目光聚焦在技術浪潮上,聚焦在那些“容易解決”的問題上,但實際上企業(yè)增長過程中還存在很多顯而易見的、需要解決的、關鍵的問題,這些問題就像“看不見的大猩猩”一樣存在于企業(yè)之中,這些問題很可能成為企業(yè)快速發(fā)展的“卡點”。
微軟中國 CTO 韋青在 2024 年 4 月舉辦的 QCon 北京發(fā)表的《看不見的大猩猩——智能時代的企業(yè)生存和發(fā)展之路》的主題演講中,結合自身經(jīng)驗,聚焦企業(yè)內(nèi)部這些被忽略的“大猩猩”,分享關鍵問題的解決之道。本文由 InfoQ 整理,經(jīng)韋青老師授權發(fā)布。
InfoQ 將于 8 月 18-19 日舉辦 AICon 上海站,我們已經(jīng)邀請到了「蔚來創(chuàng)始人 李斌」,他將在主論壇分享基于蔚來汽車 10 年來創(chuàng)新創(chuàng)業(yè)過程中的思考和實踐,聚焦 SmartEV 和 AI 結合的關鍵問題和解決之道。更多精彩議題可訪問官網(wǎng)了解:https://aicon.infoq.cn/2024/shanghai/track
思想的力量能夠把一件事情做成功不容易。在實現(xiàn)的過程中,會有很多局限。在這個新生事物層出不窮的時代,有一個常見的根本性局限,就是人的思想局限,體現(xiàn)為對事實真相辨析不明和經(jīng)常用舊的邏輯嘗試解決新的問題。
在這個世界上,對于事物真相的判斷,存在著事實、現(xiàn)象和觀點這三個不同的維度。
獲取大家公認的事實非常困難,理論上講是不可能的。因為每個人都是通過自己的“有色眼鏡”,也就是感覺器官來觀察事物,得到的是感覺器官所感受的現(xiàn)象。人們會基于個人經(jīng)歷、背景和認知偏差對所觀察到的現(xiàn)象進行解讀,從而形成自己的觀點。由于觀點都帶有主觀色彩,因此既代表現(xiàn)象,也不代表事實,只可用作討論的素材。人們有可能從基于觀點的辯論,而達成對于現(xiàn)象和事實的一致意見。
如果你看過電影《骯臟的哈里》中的演員克林特·伊斯特伍德,他在該片中有一句著名的臺詞:“觀點就像<人體的排泄出口>,每個人都有。(都有怪味,但每個人都認為自己的比別人的好聞)”。
理解了這個道理之后,我們在聽到社會上的某種流行說法時,先要明確這是某種觀點,還是大家已經(jīng)達成共識的現(xiàn)象,以及它背后所指向的事實大致是個什么樣子。不要過早地受觀點的影響,以避免陷入“看不見的大猩猩”的陷阱,被信息誤導,只關注到媒體讓我們看到的事物,而不是正在真實發(fā)生的事物。例如,現(xiàn)在我們在網(wǎng)上、在朋友圈里看到的許多現(xiàn)象,很可能都是一些具有引導性的關注點。但真正的事實是什么呢?我們需要超越表面現(xiàn)象,深入探究事物的本質。
在技術實踐中,我發(fā)現(xiàn)人的問題其實是最復雜的。雖然技術難題很難攻克,但技術畢竟是人創(chuàng)造的。一旦我們的思想方法出現(xiàn)問題,那么無論多么優(yōu)秀的人,再怎么努力,其做事的結果也非常有限。但是思想轉型是最難的,要改變思想,我們需要采用成長型思維的方式,不斷學習,不斷糾偏。這意味著我們必須認識到,我們的思想都是有偏差的,我們常常錯誤地將所觀察到的現(xiàn)象視為事實的全部,并迅速形成一種觀點,認為別人是錯的,自己是對的。在這個時代,還沒有人能夠爬上山頂,看到未來。在這個不確定性主導的世界里,未來只要還未發(fā)生,對其判斷就是一個概率問題。
人工智能的實現(xiàn)依靠計算機器基于數(shù)據(jù)而學習,數(shù)據(jù)的問題就像是一個房間里的大象,也可以說是看不見的大猩猩。說它是一頭房間里的大象,是說這個問題很明顯,但是很麻煩,大家都不愿意主動指出來。針對優(yōu)質數(shù)據(jù)的積累,它無法簡單地靠堆砌資金和人力,或者只要有海量算力就可以解決,它需要漫長的文明積累,不是所有的數(shù)據(jù)都具備可以被學習的知識,只有那些能夠表征一個文明特征的數(shù)據(jù)才能夠讓機器學到代表這種文明的知識與價值觀。說它是一頭看不見的大猩猩,是說明這個問題經(jīng)常被媒體所誤導,被大眾所忽視,人們看到的都是有關算力、算法的探討,而人工智能的實現(xiàn)是一個復雜的系統(tǒng)工程,各種前提條件缺一不可,就像一個水桶,不管構建水桶的木板有多長,它的存水量由最短的那塊板決定。人工智能就像一個孩子,是被數(shù)據(jù)培養(yǎng)出來的。如果提供給它的數(shù)據(jù)是有偏差的,那么它的行為和決策也一定是有偏差的。如果數(shù)據(jù)來自他人,那么訓練出的模型的行為和偏好也將是別人的。
對于所有企業(yè)來說,我認為第一步是顯而易見的,今天現(xiàn)場發(fā)布的報告《中國生成式 AI 開發(fā)者洞察 2024》(后臺回復「開發(fā)者洞察」即可下載)已經(jīng)給出了答案。但有時候,我們需要關注的是那些顯而易見,但大家不愿意去觸及的麻煩。例如,人才問題、數(shù)據(jù)問題、流程再造問題,這些都是我們所說的“硬核”問題。這些問題并不是多么新鮮或者偉大的問題,它們都有一個共性,就是跟腳踏實地的作風和漫長的積累相關,跟保持獨立的思想和不盲從潮流相關,與每個個體與組織愿意耐心花多長時間取得成就相關,它們需要因人、因時、因地制宜,不能簡單地復制粘貼。每個個體、每個組織都有自己的數(shù)據(jù)特征、流程特征、人才儲備和資金儲備,以及行業(yè)特征。
我們不僅應該學習別人做事的正確方法,更應該借鑒別人犯錯誤的教訓,而不是一味的想找到所謂的“最佳實踐”。因為在探索期間,就像踩雷區(qū)一樣,或者像查理·芒格所說的——智慧不是在于做對每件事,而是在于知道哪些事情是錯的。在一個極度不確定的時代,使用這種方法可能不能保證我們成功。但它能讓我們成功的概率稍微高一點,哪怕只是一點點。
如果大家仔細觀察業(yè)界所謂的成功公司,你會發(fā)現(xiàn)它們的成功大多都概率性的,只是因為活下來了,是幸存者,這種經(jīng)驗的總結很容易陷入“幸存者偏差”的陷阱。沒有人在微軟、OpenAI、英偉達、谷歌、華為、阿里、百度、騰訊等公司成立之初就敢說他們一定會成功。成功是因為他們在重要的事情上犯的錯誤少,只要不死,你生存下來的機率就變大了。因此,不是說不要向成功者取經(jīng),一是不必照搬,二是還要看看這些公司沒有做什么。

什么才是真正的思想變革?我們每個人的思想實際上都是非常固化的。特別是那些越成功、經(jīng)驗越豐富、過去成就越多的人,他們的思想往往更加難以改變,這是一個公認的事實。
在計算機歷史上,有一位非常著名且直言不諱的人物,他就是艾茲格·W·迪科斯徹。上世紀,當有人問他計算機是否能夠思考時,他回答說:“提問‘計算機是否能思考’就像問‘潛艇是否能游泳’”。他的回答正確與否并不重要,重要的是那一代計算機科學家所展現(xiàn)出的探索精神,他們不受經(jīng)驗的束縛,能夠洞察事物的本質,這種精神在當今時代尤為重要。

我再舉一個與今天更相關的例子,那就是馬車與發(fā)動機的故事。
20 多年前,麻省理工學院第一任人工智能研究室主任西摩爾·派普特提出了一個思想實驗,讓我們想象,如果一名現(xiàn)代噴氣發(fā)動機工程師穿越回 19 世紀初,向當時的馬車夫和馬車行展示噴氣發(fā)動機,并詢問這是否能幫到他們。
大家首先想到的可能是將噴氣發(fā)動機安裝到馬車上,我把這解讀為“AI+”,因為將發(fā)動機裝到馬車上,確實可以讓馬車比馬跑得更快、更省事。但這是否是我們的最終目標呢?絕對不是。我們真正要做的,是因為新工具的出現(xiàn)而重構整個行業(yè),甚至是整個社會的基本原型。
從馬車到汽車的轉變,交通的本質目的沒有變,依然是將人和物品安全、可靠、及時、高效地從一點移動到另一點。但是,如果我們用馬拉車,我們需要考慮的是在馬路上每隔兩公里設計一個草料堆與化糞池。而如果是汽車,我們則需要每隔 幾十 公里建一個加油站和服務站。無論是加油站還是化糞池,都有它們存在的必要,也都有它們存在的前提條件。都是商機,只不過是不同思想層面的商機。這種不同的思想層面代表了不同的思維范式、工業(yè)范式和文明范式。要注意這種種發(fā)展方向之間,并沒有對錯,只是因為不同的人生觀和價值觀而選擇不同的發(fā)展道路。這就是不同思想與思維方式的不同結果。
今天發(fā)布的報告《中國生成式 AI 開發(fā)者洞察 2024》已經(jīng)將這些問題闡述得非常清楚。報告中提到,首先,開發(fā)需要有場景,需要理解大語言模型的開發(fā),我將其理解為必須知道我們解決的人類問題是什么。其次,我們需要知道如何使用工具。第三,我們需要找到合適的工具。比如,如果我們要在墻上掛一幅畫,大概率我們會用到釘子或螺絲,使用錘子或螺絲刀。而如果我們在工廠里組裝一輛汽車,那么我們面臨的問題和所需的工具及方法就會完全不同。
西摩爾·派普特曾經(jīng)說過:“如果思想不改變,無論你擁有的新工具有多么先進,它又能改變什么呢?如果這個工具只是被用在馬車上的一個特別優(yōu)秀的引擎,它確實能讓馬車比馬跑得快”。在當前的流程中,我們已經(jīng)在應用人工智能工具,無論是生成式的還是傳統(tǒng)的,各種類型的人工智能工具都在被使用。這使得大家普遍感覺到,人工智能工具似乎有用,但又似乎沒有達到預期的效果。我的判斷是:雖然目前我們在使用這些工具,但最終,我們的整個社會范式將會被人工智能所改變。這意味著從“AI+”(AI 的簡單添加)到“AI 化”或“AI 乘”(AI 的深度融合和乘數(shù)效應)的轉變。

我們當前所有的話語體系都在討論應該做些什么,進行什么樣的設計,包括人工智能的生成式應用。這就引出了一個問題:人工智能是否僅限于生成式應用?傳統(tǒng)人工智能是否已經(jīng)沒有價值?我們其實并不關心它具體是哪種類型的人工智能,只要它能夠幫助我們解決問題,通過社會架構的重新構建,它就能成為一個新的工具。
理解了這個道理之后,我們可能會認識到,在做事的過程中,一方面我們需要跟隨,但我們必須記住,僅僅跟隨是永遠沒有未來的。大多數(shù)情況下我們所面對的都是概率問題。未來的一切都與概率相關,無論是貝葉斯思維還是蒙特卡洛方法。想象一下,如果我們在座的所有人都去追求同一個目標,采用同一種范式,那么我們成功的概率是多少?或者更具體地說,你能成功的概率是多少?
無論工具多么先進,即使噴氣式引擎研發(fā)得再好,如果人們想到的只是將其安裝在馬車上,那么我們很難找到新的出路。那么,汽車到底會是什么樣子?整個社會形態(tài)將如何變化?我們是否需要建立加油站、鋪設柏油馬路、設置收費站?是否需要有人開始研究整個統(tǒng)籌學、運籌學、算法優(yōu)化等科學領域,以把握先機并引領變革?
要知道我們真正需要找到的是解決某種問題的方法。那么我們的問題是什么呢?人工智能的方法很多,可以是生成式的人工智能,也可以是傳統(tǒng)的人工智能,還可以具身的人工智能。當我們要解決的問題沒明確的時候,只是談人工智能作為一種工具和方法孰優(yōu)孰劣,那也僅僅是某種觀點而已。問題是:我們作為人類,有多大的信息處理能力能夠看多少內(nèi)容?我們到底要的是機器生成的內(nèi)容還是人生的幸福感?這種幸福感是通過生成一大堆文字、圖片和視頻就能獲得,或者只是要比其他人更強,還是需要借助機器的能力擴大人類的探索邊界,擴展人類的知識,增長我們的智慧,加深我們對浩瀚宇宙真相的理解,從而讓地球文明能夠突破現(xiàn)在的局限,不再受物質與能量的束縛,進入到一個關注思想繁榮與智慧增長的信息文明時代。我認為對于這些問題的回答將決定下一步的人工智能何去何從。
機器的使命回顧一下機器的概念,在這里我引用了微軟董事長兼 CEO 薩提亞·納德拉經(jīng)常引用的來自道格拉斯·恩格爾巴特的觀點。道格拉斯·恩格爾巴特是當代計算機文明的奠定者之一,他的技術愿景和對于人類社會發(fā)展的洞察仍然指導著當前計算機器的發(fā)展方向。恩格爾巴特持有與范內(nèi)瓦·布什和司馬賀這些思想家相似的觀點,都認為人類社會接下來最大的挑戰(zhàn)就是因為信息過載而造成的復雜度已經(jīng)遠遠超出了人類所能夠處理的范疇,信息技術提升了人類社會效率,也加大了復雜度,我們需要計算機器幫助我們處理因為計算機器所帶來的問題。

人類作為一種碳基動物,通過我們的五種傳感器感知周邊的世界,再通過神經(jīng)傳導的電化學作用將我們用傳感器從周圍世界感知的信號傳送至我們的大腦進行處理與加工。由于信息量的泛濫和通訊的普及,再加上大多數(shù)人類的思想能力還沒有進化到可以有節(jié)制地使用我們的大腦信息處理能力,一味不加選擇和節(jié)制地攝入信息,就是得我們的大腦像暴飲暴食的身體一樣,開始出現(xiàn)了大腦“肥胖癥”。當然,人類經(jīng)過多年的工業(yè)文明熏陶,已經(jīng)知道我們的身體不能隨意攝入垃圾食品,我們開始有所選擇,有所判斷。那我們是怎樣對待大腦的呢?讓我們反思一下,從今天早上醒來到現(xiàn)在,你所看到的消息中,哪些是真的,哪些是假的,哪些是半真半假的,哪些是有偏差的,哪些是欺騙你的,哪些是對你有幫助的,哪些是無用的,哪些是虛構的?
實際上,我們大多數(shù)人并沒有深思熟慮,而是直接接受了這些信息。大家再回想一下,從今天早上醒來到現(xiàn)在,你所看到的消息,你還記得多少?記住的信息中,又有多少是真正能夠用得上的?我們的大腦是在空轉,不斷地攝入“垃圾食品”,還是真正吸收到了有用的信息,讓我們的思維能力得到提升?
在討論接下來的實操內(nèi)容之前,我想強調,在這個時代,能夠“不被騙”就是最大的優(yōu)勢。我們所比拼的是什么呢?是智商、情商、理商。我現(xiàn)在再加上一個信商,即信息智商。我們搞 IT 的都知道網(wǎng)絡信息安全有“零信任”原則,那么在面對信息攝取時,我們是否也應該采取信息攝取的“零信任”態(tài)度呢?
“看不見的大猩猩”的作者在 2023 年又寫了一本書,名為《沒有人是傻瓜》。他在書中提出,每個人都應該遵循的原則是“少信一點,多驗證一點”。我們應該默認所有由像素生成的信息,大概率都有可能是假的。我們也應該像網(wǎng)絡一樣,對所有像素構成的信息采取零信任的態(tài)度,然后訓練出我們自己的算法來幫助我們鑒別信息的真?zhèn)巍7駝t,我們這些工程師、科學家可能會被一些信息誤導,不是受人制約,,而是被人騙,被人牽著鼻子到處亂跑,誤以為自己走對了方向。我們天天去學習別人的最佳實踐,天天去學習標準答案,卻忽略了一個最基本的事實:我們已經(jīng)進入了一個開卷考試的時代,現(xiàn)在最不缺的就是標準答案,最缺的是經(jīng)過獨立思考而得到的適合我們自己的答案。
接下來,我想簡單地展望一下未來。我認為現(xiàn)在有很多人在還沒有開始攀登之前,就拼命想象山頂會是什么樣子,是好是壞,是否可行。但實際上,大多數(shù)人甚至還沒有開始他們的旅程。就目前而言,我認為智能機——不要過分夸大其作用,它就是一個智能機——但它所開創(chuàng)的,是幫助人類了解極大、極小、極遠、極近的領域。所謂極大指的是宇宙,極小指的是量子,極遠指的是太空,而極近則是更深入地了解我們自己,最終理解我們是誰。
現(xiàn)在的智能機以非常高的效率,推動了"AI for Science"(科學智能)和"AI for Everyone"(人人智能)的發(fā)展,尤其是"AI for Science",科學探索得到智能機的加持后,其研究進展的速度是驚人的。如果你了解一下當前生物學、細胞學、醫(yī)學以及量子物理學界的研究進展,你會發(fā)現(xiàn)這些進展遠遠超出了我們對生成式人工智能的想象。微軟在英國劍橋的 AI 研究院,已經(jīng)轉向"AI for Science"的研究,并取得了許多突破,包括在材料科學領域的應用。眾所周知,我們?nèi)祟悓τ谧陨怼τ诹孔訉用娴睦斫膺€是非常有限的,而機器在這些方面可以提供巨大的幫助,比如在分子、原子、細胞、DNA\線粒體、材料、能源構成等領域,還有很多未知等待我們?nèi)ヌ剿鳌?/p>
目前我們所觀察到的,比如制作圖片、視頻或生成文字等,這些在辦公自動化中非常有用,但它們只是智能機器能力的一個狹小的領域,。我在下圖提到了一些可能性,并用紅色進行了標注。但這些也只是美好的愿景,它們需要落地實現(xiàn),智能技術的落地也是有次第可循的邏輯。
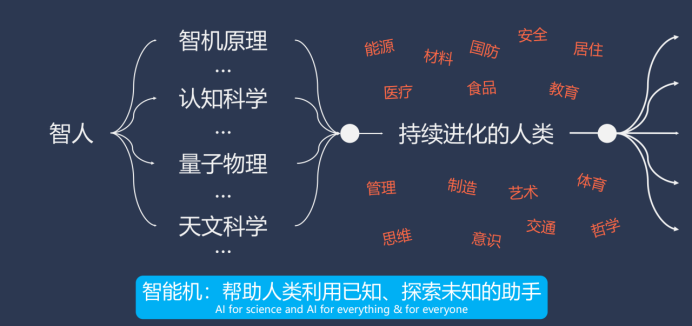
落地的次第我之所以一開始講述這么多有關思想與觀念的話題,是因為如果我們不能夠放下我們每個人,尤其是成功人士的思想成見,放下我們思想中的歷史包袱,我們接下來的行動很可能只是在馬車上裝上一個引擎,比拼誰的馬車裝上引擎后跑得更快,而不是認識到汽車雖然開始時可能比你的馬車跑得慢,但最終汽車必將遠遠超越馬車。換句話說,對我們來說,每個人的挑戰(zhàn)在于,我們可能仍然固守在要給馬車裝上引擎的想法上,因為我們需要活在當下,但我們需要開始意識到我們的目標不是如何將馬車打造得更好,裝上多少引擎,或者如何改造它,而是要開發(fā)出一整套全新的汽車架構和現(xiàn)代化交通體系。
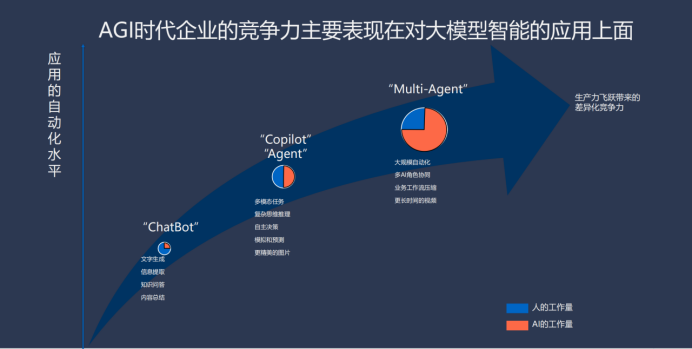
我相信大家對下圖所展示的架構已經(jīng)有所了解,它從基礎架構出發(fā),經(jīng)過應用架構,再到開發(fā)的架構,最后落實到具體的應用場景。雖然這是一個顯而易見的過程,但是即便如此明顯,真正能夠找到用戶實際需要的應用的人卻微乎其微。
我的觀點是:“知道山在那里,并不意味著你就能登上山頂;而在山腳下,你也無法確定這是不是最高的山峰。”盡管學習、觀察和借鑒他人是非常重要的,但這些只是必要條件,并不是充分條件。即便你知道山的位置,即便你有一張登山地圖,這也只是其中的一部分真相。地圖并不是真正的現(xiàn)場,而且所有的地圖都是別人已經(jīng)走過的路。
我印象最深的是,在讀書學工程的時候,曾經(jīng)調整過 PID 參數(shù)。第一次調整 PID 參數(shù)時感到很困惑:書上的理論知識都是正確的,函數(shù)也寫對了,但電動機就是在那里抖動。書本的知識和實際現(xiàn)場出現(xiàn)的情況是不一樣的。因此,親身實踐和實證非常關鍵。學習到一定程度固然重要,但最終還是要自己找到解決方案,找到適合自己的方法。
大家在觀察許多人工智能的開發(fā)模型和范式時,可能會注意到有很多夸張的宣傳,很多講解傾向于“一劍封喉”的斷言,只要這樣做就有那樣的結果。但只要一種思維邏輯具象為一種具體的方法,就會有它適用的前提條件約束。只有回歸到它的思維邏輯,才能夠讓借鑒者根據(jù)具體情況具體分析與解決。
首先,智能機需要明確理解其目的;其次,它需要理解自身的能力邊界;第三,它必須了解其操作的約束條件,也就是它所處的約束空間。接下來,智能機需要有能力尋找可用的外部資源和工具,然后開始有步驟地拆解任務,決定是順序執(zhí)行還是并行執(zhí)行。在執(zhí)行過程中,還需要一個實時的反饋鏈,也就是持續(xù)的反饋機制,不斷行動,不斷糾偏。
現(xiàn)在在網(wǎng)上,有些人將“reflection”翻譯為“反思”,這種翻譯是有問題的。機器真的會反思嗎?實際上,機器只是在反饋的基礎上,針對它的預測進行計算糾偏,而并不會像人類那樣進行深入的反思。因此,我們不應該將描述人類思維的詞匯用在機器上,這樣做是非常危險的,因為它可能會導致我們對機器的能力作出錯誤的判斷。

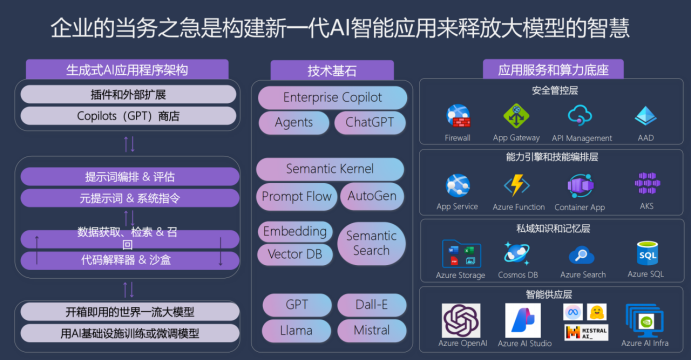
理解了上述內(nèi)容之后,我們可以進一步抽象化地看問題。實際上,我們每天從早到晚都在進行人 - 機協(xié)同的工作。作為個體,我們每個人都有自己明確的目標。在下圖中,用紅色表示人類正在執(zhí)行的任務,用藍色表示機器正在執(zhí)行的任務。想想看,從今天早上起床到現(xiàn)在,無論是坐車、打車、開車來,還是聽課、看手機,我們是不是一直在這樣與機器協(xié)同工作?這種協(xié)同工作會出現(xiàn)什么樣的現(xiàn)象呢?真正的機會在于我們是否能夠識別出我們的痛點是什么。一旦我們識別出了自己的痛點,如果這種痛點可以由機器輔助,就成為智能機可以發(fā)揮作用的地方。熟悉 TRIZ 創(chuàng)新方法論里面 TESE 方法的人可能就看出,其實這就是逐步減少人類參與的系統(tǒng)創(chuàng)新方法,并不是什么突然出現(xiàn)的話題,只不過隨著人類所發(fā)明的工具的進步,創(chuàng)新的方法也在不斷演變之中。對于這一輪的智能機器而言,數(shù)據(jù)是核心,也就凸現(xiàn)出過去幾十年一直強調數(shù)字化的重要性。

沒有數(shù)據(jù)就無法實現(xiàn)智能算法,沒有數(shù)字化就沒有數(shù)據(jù)。因此,我們?nèi)匀恍枰M行數(shù)字化改革。一旦我們理解了這個基本原理,就會發(fā)現(xiàn)有很多問題就像是屋子里的大象,雖然沒人直接談論,但它們卻明顯地擋在我們前進的道路上。
僅有人才的思想解放、組織的重構和流程的再造是不夠的。為了實現(xiàn)數(shù)字化轉型,我們還需要結合數(shù)字化產(chǎn)品和實時反饋鏈,以及整個產(chǎn)業(yè)鏈的協(xié)同。這不僅僅是個體和公司層面的事情,還需要整個生態(tài)系統(tǒng)中上下游合作伙伴的相互匹配和協(xié)調。在這種情況下,數(shù)據(jù)才是真正為了 AI 而生的數(shù)據(jù)。
作為一間合資公司的總經(jīng)理,我也管理著公司,當公司試圖利用智能機器的能力優(yōu)化公司的客戶服務時,我們也以為已經(jīng)積累了很多服務數(shù)據(jù),可以很方便的實現(xiàn)服務的智能化了吧?但當你嘗試將 AI 應用上去時,會發(fā)現(xiàn)這些過去積累的數(shù)據(jù),其建模方式并沒有針對智能機器算法而優(yōu)化,可用,但效果并不好。為什么?人們常常誤以為機器可以學習任何東西,尤其是非結構化數(shù)據(jù),我認為這是一個非常誤導人的說法。捫心自問,機器真的能學習非結構化數(shù)據(jù)嗎?機器學習真的能學習沒有標簽的數(shù)據(jù)嗎?所謂的非監(jiān)督學習,其監(jiān)督已經(jīng)內(nèi)嵌在了提供給它的數(shù)據(jù)結構中。也就是說,數(shù)據(jù)本身必須帶有邏輯,機器才能從中學習。真給機器丟一堆沒有內(nèi)在模式的數(shù)據(jù),它是不可能憑空識別出模式的。
只有擁有數(shù)據(jù),我們才能獲得真正的知識,然后再將這些知識轉化為 Copilot,加入到每一個流程中去。我認為這將是未來作為人類智能助手的終極解決方案。這也與我之前提到的報告相呼應,實際上并不存在哪個行業(yè)或工作內(nèi)容不會被重構,所有可以被拆解成流程的工作都將被重構。
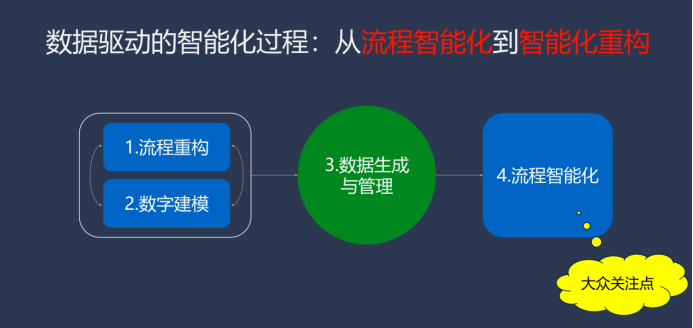
流程中的一個關鍵點是必須同時滿足人類能理解和機器能處理的條件。回顧歷史,這實際上是真正的 Web 3.0 概念,也就是十多年前的語義網(wǎng),那時語義網(wǎng)技術被稱為 Web 3.0 技術。這里的關鍵不在于術語本身,而在于其內(nèi)涵,我們的整體愿景是將我們的生活、世界和社會構建成既能被人理解也能被機器處理的形式。我們每家公司的領域知識、專家知識,以及行業(yè)知識是否都能被建模,以至于機器能理解和處理呢?以目前流行的售后服務數(shù)字化和智能化為例,你的知識庫真的能夠做到既被機器理解也能被機器處理嗎?以我的經(jīng)驗來看,這通常需要重新構建。這里重點是關注流程的智能化和智能社會的構建,無論是 AI 加法還是 AI 乘法,實際上都要考慮重構,而不是簡單地在馬車上加一個引擎。
精心打磨流程重構、數(shù)字建模,實現(xiàn)數(shù)據(jù)生成與管理,進而實現(xiàn)流程智能化。但遺憾的是,大多數(shù)人關注點都集中在最后一點,即流程智能化,而忽視了前三點。前三點是整個金字塔的基座,如果基座不穩(wěn)固,整個結構將會動搖。此外,還有第五點,即“人在循環(huán)中”。因為機器并非萬能,因此人與機器的結合是非常關鍵的,但這還不夠。在第五點之上是第六點,即“人在環(huán)路上”,涉及到控制論的一階、二階和三階控制與優(yōu)化,也可稱為一階、二階和三階的學習過程,是對做事的“為什么做 - 做什么 - 如何做”(Why-What-How) 的反向優(yōu)化過程,與機器學習所依賴的反向傳播機制在概念上是相通的。
我們現(xiàn)在要做的第一步是將所有流程重構,讓機器完成工作,賺取利潤。但為了預見最終到達的位置,還必須建立一個新的人機文化。如果僅僅關注機器或技術能做什么,而不將人的因素考慮在內(nèi),這樣的企業(yè)是不可能長久的。
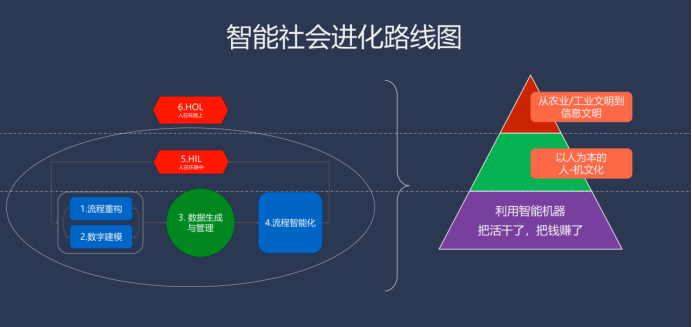
最后,我想談談信息文明的最顯著特征,那就是避免被欺騙,這種能力也會被別有意圖的人利用來進行欺騙。我們現(xiàn)在生活在一個信息社會中,真的能夠辨別出對自己有用的信息,并據(jù)此做出正確的判斷嗎?我認為這是非常困難的。我們每個人都被包裹在自己的信息繭房中,只能看到我們想看到的,只能聽到我們想聽到的。那么,我們?nèi)绾未_保自己不會被這個看不見的大猩猩——信息繭房所限制呢?這是對我們每個人的最大挑戰(zhàn)。
今天,我分享這些內(nèi)容,是因為我認為如果不解決這個問題,僅僅偶爾得到一些答案,偶爾成功一下,是遠遠不夠的。因為如果沒有建立起對未來技術發(fā)展的堅定信念,那么偶爾的成功并不能代表最終的成功。這是我從微軟的一些工程師那里聽到的他們的心態(tài)歷程,現(xiàn)在分享給大家。微軟的 CEO、董事長薩提亞·納德拉在 2022 年 5 月就已經(jīng)提到了 ChatGPT、OpenAI、Copilot 等概念。2022 年 11 月底 ChatGPT 發(fā)布后,大家蜂擁而上。微軟的工程師其實也經(jīng)歷了這樣的過程。起初是“AI+”,將 AI 應用到所有事物上,但第一代產(chǎn)品發(fā)布后發(fā)現(xiàn)效果不佳,那還只是一輛馬車。
因此,他們轉向了“Everything for AI”,即利用新的工具重構產(chǎn)品的流程和使用方法,包括人機交互界面、流程、判斷和執(zhí)行。最終他們發(fā)現(xiàn),關鍵不在于 AI、數(shù)據(jù)、顯卡或算法,而在于解決人世間的風花雪月、衣食住行。我們的產(chǎn)品如果能夠解決人類的基本需求,就一定具有生命力。如果你的觀點只局限于一個噴氣發(fā)動機或者一輛馬車上,那么我認為你不會取得太大的成就。
今天的標題是“大模型正在重新定義軟件”。大模型是什么?“正在”是什么?重新定義軟件所代表的結果是把軟件視為一輛馬車加上一個引擎,稱之為重新定義,還是真正地重新定義軟件工程、軟件流程,改變整個軟件的生命周期?
微軟研究院的一些研究員專門研究“AI for software engineering”,我認為這可能就是大家在軟件開發(fā)行業(yè)即將面臨的未來。當我們還在認為在馬車上加引擎的時候,已經(jīng)有一些人開始意識到這只是暫時的現(xiàn)象。我們真正要的是一個現(xiàn)代化的、以汽油、柴油驅動的交通體系。而在 100 年后,我們發(fā)現(xiàn)這個交通體系實際上是由電力驅動的。這將是我們未來幾十年面臨的機會與挑戰(zhàn)。
- 推薦
- 新聞
- 觀點
- IT/互聯(lián)網(wǎng)
- 軟件信息
- CIO
- CDO
- 工業(yè)互聯(lián)網(wǎng)
- 智能制造
- 人工智能
- 戰(zhàn)略
- 研發(fā)
- 生產(chǎn)制造
- 運營
- 市場營銷
- IT




推薦

一年一度的中國數(shù)字化年會將于11月28日-30日再次攜手成都,為數(shù)字化轉型決策者們打造一場不可錯過的年度數(shù)字化盛宴!

在這個日新月異的變革時代,我們將于11月28日-30日在成都舉辦“2024中國數(shù)字化年會”,匯聚行業(yè)精英與各界力量,共同探討數(shù)字化時代下的轉型策略與路徑。

11月28日-30日,中國數(shù)字化年會將于成都正式開幕,本屆年會以數(shù)智萬象 無界新生”為主題,設置2場主論壇、1場高峰論壇、5場專題論壇、4項特色活動、2場頒獎典禮等14項活動,以及2天數(shù)字化轉型供需對接展。

零次方科技發(fā)布了其首款人形機器人,可以在多種不規(guī)則路面、復雜地形中長時間穩(wěn)定行走,且具備優(yōu)秀的抗干擾性能,即使受到各方向的強沖擊也能保持穩(wěn)定站立。

近日,第四屆“青年科學家502論壇”在南方科技大學舉行,美國國家工程院外籍院士沈向洋做了《通用人工智能時代,我們應該怎樣思考大模型》的主題演講,并給出了他對大模型的10個思考。
深度解析Meta Reality Labs的生態(tài)布局


 15356
15356 15283
15283 17672
17672 16761
16761 15110
15110中關村大數(shù)據(jù)產(chǎn)業(yè)聯(lián)盟 顏陽-元宇宙產(chǎn)業(yè)的商業(yè)邏輯與技術壁壘研究
顏陽 中關村大數(shù)據(jù)產(chǎn)業(yè)聯(lián)盟副秘書長 ¥9.90 金錦囊免費
 13855
13855




我要評論